| 帝国CMS采集正则介绍与写法。 |
|
| 帝国CMS的采集正则 | |||||||||
| 1、作用:通过设置采集正则以便使系统识别你要采集的内容。 | |||||||||
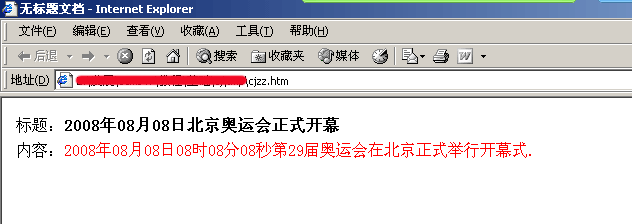
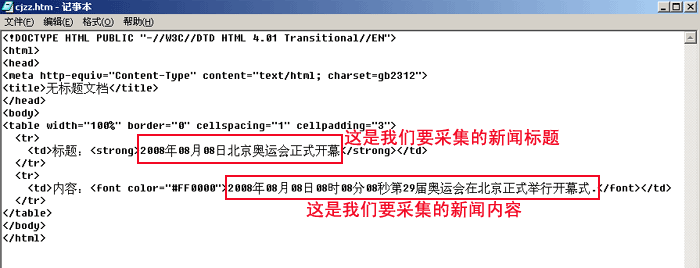
| 2、帝国CMS的采集正则是什么样的,下面我们用实例讲解: | |||||||||
|
|||||||||
| 3、帝国CMS正则还有表示任意内容的字符:“*” | |||||||||
如果“识别代码头部”中有内容是变化的,那么我们可以用*代替它。如页面源代码为如下,我们要采集下面的链接地址:
|
|||||||||
| 4、其他说明: | |||||||||
(1)、正则要找出唯一性的开头字符。有时候空格都会成为识别的依据。 |
|||||||||
| (2)、对于特殊字符请在前面加上“\\”,当然直接将特殊字符改为“*”最合适了。特殊字符如下: “ )”、“(”、“{”、“}”、“[”、“]”、“\”、“?”等等。 |